This vignette is designed to aid users in preparing their data for use with devMSMs. Users should first view the Terminology and Specifying Core Inputs vignettes.
The code contained in this vignette is also available, integrated code from the other vignettes, in the ExampleWorkflow.rmd file.
Data Requirements
We recommend considering several data requirements prior to using devMSMs and any of the vignettes.
MSMs are most useful for strengthening causal inference using longitudinal data that include an exposure and confounders that vary in time prior to an outcome. At a minimum, devMSMs requires two time point data with an exposure measured at least once and an outcome measured at the second time point, and at least one confounder. The exposure can be binary (with integer class) or continuous (with numeric class), and there are no assumptions about the distributions of outcome or confounders. We highly recommend using continuous variables when appropriate and possible to avoid the information loss inherent to binarizing a continuous variable. Although there is no gold standard recommendation, we suggest users select exposures that have some within-person variation from which it would be reasonable to delineate different histories of “high” and “low” levels and avoid extrapolation.
The outcome time point must be the last time point when exposure was measured or a time point after the last exposure measurement time point. For cases in which the outcome variable constitutes a growth process at the final time point, we advise choosing a reasonable measure for balancing purposes (e.g., baseline or average levels) before subsequently using the generated weights to separately conduct a weighted growth model of the outcome.
We advise the user to specify and include in the dataset any time invariant and time-varying variables that could possibly confound the relation between exposure and outcome. We also suggest using multiple measured variables within each construct to help reduce any effects from measurement bias (Kainz et al., 2017). Time varying confounders are ideal for maximizing the power of MSMs. Time-varying confounders could include developmental indicators that tend to track with the exposure over time that could also cause the outcome, including past levels of the exposure. Of note, the time points at which the confounders were collected must be equal to, or a subset of, the time points at which the exposure and outcome were collected in the data. In a perfect world, all exposures and potential confounders would be measured at all time points prior to the outcome. However, with real-world data due to planned and unplanned missingness, this is often not the case. Users should consider discussing the implications and limitations conferred by variables that could be confounders that were not collected at all time points. As a basis for specifying confounders, users should turn to the literature to delineate a causal model that lays out hypothesized relations between confounders, exposures, and outcome.
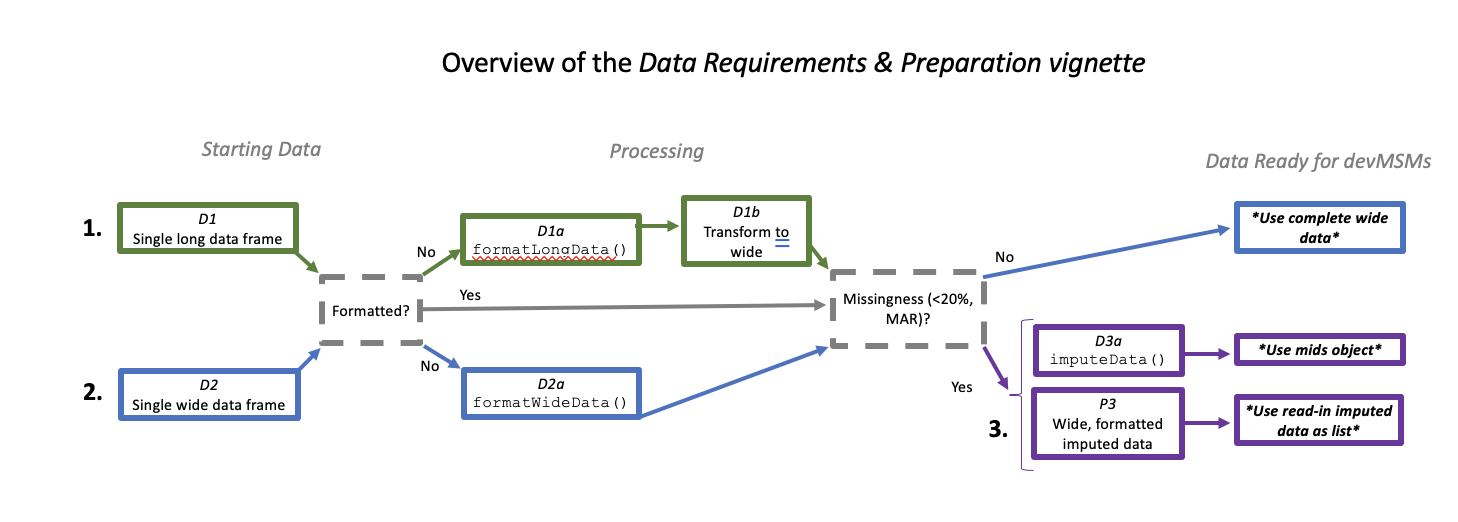
We advise users implement the appropriate preliminary steps, with the goal of assigning to ‘data’ one of the following wide data formats (see Figure 1) for use in the package:
a single data frame of data in wide format with no missing data
a mids object (output from mice::mice()) of data imputed in wide format
a list of data imputed in wide format as data frames.
As shown in the figure below, for use of the devMSMs package, data in any of the above 3 formats, must be wide and contain an “ID” column for subject identifier and exposure, outcome, and all confounders as separate columns (as shown in Figure 1). Column names can include only underscore special characters and time-varying variables should have a suffix that consists of a period followed by the time point (e.g., “variable.6”). All variables should be classed as integer, numeric, or a factor (not character). Auxiliary or nuisance covariates that are not confounders (e.g., assessment version) can be included in the dataset for use and specification in the final outcome modeling step (Workflow vignettes Step 5).
#> id ti_X tv_Y1.1 tv_Y1.2 tv_Y2.1 tv_Y2.2 exposure.1 exposure.2 outcome.2#> 1 1 0.5 50 65 NA 0.04 3 4 80#> 2 2 NA 33 57 0.08 0.03 5 3 68#> 3 3 0.3 68 NA 0.01 0.02 6 8 59
Abridged example structure of a wide dataset formatted as required
for the devMSMs. Column A denotes the ID variable, column B (green)
denotes a time in-variant confounder (e.g., race, birth information),
columns C - F denote two time-varying confounders (lighter yellow) at
two different time points (e.g., age.1, age.2 and income.1, income.2,
where .1 represents wave 1 and .2 represents wave 2). Columns G - I
denote the exposure and outcome of interest (darker yellow), where G and
H are time-varying values on each exposure, and column I is the outcome
value at the final wave/timepoint. Missing data are denoted as
NA and will need to be imputed (Step P2).
The following longitudinal data that accompany devMSMs are simulated based on data from the Family Life Project (FLP), a longitudinal study following 1,292 families representative of two geographic areas (three counties in North Carolina and three counties in Pennsylvania) with high rural child poverty (Vernon-Feagans et al., 2013; Burchinal et al., 2008). We take the example exposure of economic strain (ESETA1) measured at 6, 15, 24, 35, and 58 months in relation to the outcome of behavior problems (StrDif_Tot) measured at 58 months.
devMSMs (see Workflows vignettes) requires complete data in wide format (i.e., one row per individual, with and “ID” column for identifiers), in one of three ways:
The helper functions (summarized in Table 1) for the following recommended preliminary steps can be found at this Github. Of note, devMSMs must also be installed and loaded to use these helper functions (see Installation).
#> [1] "<S4 class 'tinytable' [package \"tinytable\"] with 57 slots>"
We first install the devMSMs and devMSMsHelpers packages.
Preliminary steps P1 (formulate hypotheses) and P2 (create a DAG) are detailed further in the accompanying manuscript. These following recommended preliminary steps are designed to assist the user in preparing and inspecting their data to ensure appropriate use of the package.
P3. Specify Core Inputs
Please see the Specifying Core Inputs vignette for more detail on the following core inputs. Here, we use ESETA1, a measure of economic strain experienced by the family, as the exposure and StrDif_Tot, or behavior problems measured by the SDQ, as the outcome.
Some helper functions have optional arguments to suppress saving output locally (save.out = FALSE) and printing it to the console ( verbose = FALSE). The defaults to both arguments are TRUE. Users must supply a path to a home directory if save.out = TRUE.
save.out<-FALSEverbose<-TRUE
As shown in the Figure below, users have several options for reading in data. They can begin this workflow with the following options:
(P4.1) long data: complete or with missingness that can be formatted and converted to wide data and (P4.3) imputed as needed
(P4.2) wide data: complete or missingness that can be formatted and (P4.3) imputed as needed
(P4.3) data already imputed in wide format can be read in as a list
Figure 2. Schematic of recommended preliminary steps showing the transformation of the different kinds of starting data to the three kinds of data accepted by devMSMs.
P4.1. Single Long Data Frame
Users beginning with a single data frame in long format (with or without missingness) can utilize a helper function formatLongData() to summarize exposure and outcome data and convert to required variable names.
First, we load the simulated longitudinal data in long format (with missingness) that accompanies devMSMs. These data are simulated based on data from the Family Life Project (FLP), a longitudinal study following 1,292 families representative of two geographic areas (three counties in North Carolina and three counties in Pennsylvania) with high rural child poverty (Vernon-Feagans et al., 2013; Burchinal et al., 2008). We take the example exposure of economic strain (ESETA1) measured at 6, 15, 24, 35, and 58 months in relation to the outcome of behavior problems (StrDif_Tot) measured at 58 months.
For long data that is not correctly formatted, formatLongData() allows the users to supply existing variables for time (time_var), ID (id_var), and missing data (missing) for re-naming according to what is required by the package. It also allows the user to submit variables that should be factors and integers, and the function classes any factor confounders (factor_confounders) as factors, integer confounders (integer_confounders) as integers in the data, and all others as numeric. The sep field allows you to specify a delimeter for the integer that indicates time point in the variable names.
We get a descriptive statistics summary of the exposure, ESETA1, and the outcome, StrDif_Tot.58, for our visual inspections.
P4.1b. Tranform Formatted Long Data to Wide
Users with correctly formatted data in long format have the option of using the following code to transform their data into wide format, to proceed to using the package (if there is no missing data) or imputing (with < 20% missing data MAR).
We then transform our newly formatted long data into wide format, specifying idvar as “ID”, timevar as “WAVE”, and supplying the time points (encompassing exposure, confounder, and outcome time points) in the data as 6, 15, 24, 35, and 58 to times.
Users beginning with a single unformatted data frame in long format can utilize a helper function formatWideData() to summarize exposure and outcome data and convert to required variable names. formatWideData() allows the users to supply existing variables for ID (id_var) and missing data (missing) for re-naming according to what is required by the package. It also allows the user to submit variables that should be factors and integers, and the function classes any factor confounders (factor_confounders) as factors, integer confounders (integer_confounders) as integers in the data, and all others as numeric. The user can also specify a time point delimeter (sep).
Below, we format the simulated wide FLP data by listing out variables to make into factors and integers in wide format (e.g., “variable.t”), as well as the ID and missingness indicators.
The functions of the devMSMs package accept data in the form of a single data frame with no missing values or m imputed datasets in the form of either a mids object (output from the mice package or via imputeData()) or a list of imputed datasets. Most developmental data from humans will have some amount of missing data. Given that the creation of IPTW balancing weights requires complete data, we recommend imputing data. Imputation assumes a missing data mechanism of missing at random (MAR) and no more than 20% missing data in total (Leyrat et al., 2021). Given existing work demonstrating its superiority, devMSMS implements the ‘within’ approach for imputed data, conducting all steps on each imputed dataset before pooling estimates using Rubin’s rules to create final average predictions in order to make contrast comparisons in Worfklows vignettes Step 5 (Leyrat et al, 2021; Granger et al., 2019).
As shown below, users can use a helper function to impute their wide data or impute elsewhere and read in the imputed data as a list for use with devMSMs.
P4.3a. Multiply Impute Formatted, Wide Data Frame using MICE
Users have the option of using the helper imputeData() function to impute their correctly formatted wide data. This step can take a while to run. The user can specify how many imputed datasets to create (default m = 5). imputeData() draws on the mice() function from the mice package (van Buuren & Oudshoorn, 2011) to conduct multiple imputation by chained equations (mice). All other variables present in the dataset are used to impute missing data in each column. Given existing work demonstrating its superiority, devMSMs implements the ‘within’ approach for imputed data (Granger et al., 2019; Leyrat et al., 2021), conducting all steps on each imputed dataset before pooling estimates using Rubin’s rules to create one final set of average predictions and history comparisons.
The user can specify the imputation method through the method field drawing from the following list: “pmm” (predictive mean matching), “midastouch” (weighted predictive mean matching), “sample” (random sample from observed values), “rf” (random forest) or “cart” (classification and regression trees). Random forest imputation is the default given evidence for its efficiency and superior performance (Shah et al., 2014). Please review the mice documentation for more details.
Additionally, users can specify an integer value to seed in order to offset the random number generator in mice() and make reproducible imputations.
The parameter read_imps_from_file will allow you to read already imputed data in from local storage (TRUE) so as not to have to re-run this imputation code multiple times (FALSE; default). Users may use this parameter to supply their own mids object of imputed data from the mice package (with the title ‘all_imp.rds’). Be sure to inspect the console for any warnings as well as the resulting imputed datasets. Any variables that have missing data following imputation may need to be removed due to high collinearity and/or low variability.
The required inputs for this function are a data frame in wide format (formatted according to pre-requirements listed above), m number of imputed datasets to create, a path to the home directory (if save.out = TRUE), exposure (e.g., “variable”), and outcome (e.g., “variable.t”). The home directory path, exposure, and outcome should already be defined if the user completed the Specifying Core Inputs vignette.
The optional inputs are as follows.
The user can specify an imputation method compatible with mice() (see above). Additionally, the user can specify in maxit the number of interactions for mice::mice() to conduct (default is 5). The user can also specify para_proc, a logical indicator indicating whether or not to speed up imputing using parallel processing (default = TRUE). This draws on 2 cores using functions from the parallel, doRNG, and doParallel packages.
The user may also specify any additional inputs accepted by mice::mice() and we advise consulting the [mice documentation] for more information.
The user can also indicate if they have already created imputed datasets from this function and wish to read them in (read_imps_from_file = TRUE) rather than recreate them (default).
For this example, we create 2 imputed datasets using the default random forest method and 0 iterations (just for illustrative purposes), set a seed for reproducibility, and assign the output to data for use with devMSMs. This code takes some time to run. (Note: given the challenges of imputing data from .rda files, we have set m = 2 and maxit = 0 here just for illustrative purposes. We recommend setting both m = 5 and maxit = 5 (mice default) when running data.)
s<-1234m<-2method<-"rf"maxit<-0imputed_data<-imputeData( data =data_wide_f, exposure =exposure, outcome =outcome, sep ="\\.", m =m, method =method, maxit =maxit, para_proc =FALSE, seed =s, read_imps_from_file =FALSE, home_dir =home_dir, save.out =save.out)#> Creating 2 imputed datasets using the rf imputation method in mice::mice(). This may take some time to run. #> #> #> USER ALERT: Please view any logged events from the imputation below: #> Table: Logged Events from mice::micehead(mice::complete(imputed_data, 1), n =c(5, 10))#> ALI_Le.35 B18Raw.15 B18Raw.24 B18Raw.58 B18Raw.6 BioDadInHH2 caregiv_health#> 1 3 1 1 0 -4 1 3#> 2 2 5 -7 7 0 0 0#> 3 3 6 5 20 -1 0 3#> 4 4 24 25 17 11 0 3#> 5 3 -8 1 3 1 1 2#> CORTB.15 CORTB.24 CORTB.6#> 1 -0.227 -0.652 0.742#> 2 0.654 0.397 0.018#> 3 1.145 0.033 -0.379#> 4 0.301 -0.501 0.000#> 5 -0.247 0.084 0.153data<-imputed_data
We inspect the output to the console for any warnings from mice().
The mice object can now be assigned to data for use in the deveMSMs package (see Workflows vignettes).
P4.3b. Read in as a List of Wide Imputed Data Saved Locally
Alternatively, if a user has imputed datasets already created from wide, formatted data using a program other than mice, they can read in, as a list, files saved locally as .csv files in a single folder. This list can be assigned to data for use in the deveMSMs package (see Workflows vignettes).
Below, we load in a list of imputed data simulated from FLP, as an example. (See the example Rmarkdown file for code to do this with files saved locally.)
Burchinal, M., Howes, C., Pianta, R., Bryant, D., Early, D., Clifford, R., & Barbarin, O. (2008). Predicting Child Outcomes at the End of Kindergarten from the Quality of Pre-Kindergarten Teacher–Child Interactions and Instruction. Applied Developmental Science, 12(3), 140–153. https://doi.org/10.1080/10888690802199418
Granger, E., Sergeant, J. C., & Lunt, M. (2019). Avoiding pitfalls when combining multiple imputation and propensity scores. Statistics in Medicine, 38(26), 5120–5132. https://doi.org/10.1002/sim.8355
Kainz, K., Greifer, N., Givens, A., Swietek, K., Lombardi, B. M., Zietz, S., & Kohn, J. L. (2017). Improving Causal Inference: Recommendations for Covariate Selection and Balance in Propensity Score Methods. Journal of the Society for Social Work and Research, 8(2), 279–303. https://doi.org/10.1086/691464
Leyrat, C., Carpenter, J. R., Bailly, S., & Williamson, E. J. (2021). Common Methods for Handling Missing Data in Marginal Structural Models: What Works and Why. American Journal of Epidemiology, 190(4), 663–672. https://doi.org/10.1093/aje/kwaa225
Vernon-Feagans, L., Cox, M., Willoughby, M., Burchinal, M., Garrett-Peters, P., Mills-Koonce, R., Garrett-Peiers, P., Conger, R. D., & Bauer, P. J. (2013). The Family Life Project: An Epidemiological and Developmental Study of Young Children Living in Poor Rural Communities. Monographs of the Society for Research in Child Development, 78(5), i–150.